
We are pleased to release v1.0 of the CMIP7 Data Request.
On this Page
There are two key components of the request that you can access from today:
If you would like more information about the new structure of the Data Request for CMIP7, or some background information about how the Data Request has been created so far, you can find this at the bottom of this page.
The Data Request content
The CMIP7 Data Request contains the list of variables and their associated metadata which are requested from CMIP7 experiments. In v1.0, the list of experiments is limited to the AR7 Fast Track. Later version of the Data Request will include additional experiments outside of the Fast Track.
The Data Request contains a subset of variables which were requested in CMIP6, alongside a suite of new variables. While the Data Request Task Team and thematic author groups have worked incredibly hard to get v1.0 of the Data Request into a finalised format, there is ongoing work to update and correct issues in the content. We have outlined some of these efforts below so users can access and use the Data Request content with a full understanding of the status of the variables, variable groups, and Opportunities.
Variables with known issues
A few variables have known technical errors that were not possible to fix before the v1.0 release. This includes variables which are still pending a new CF Standard Name or variables with ongoing discussions around how to implement their metadata within the Data Request structure. Variables which are known to have an issue are flagged in the field ‘Flag – known issue’, with the known issue detailed in the ‘Processing note’ field.
Changes in CMIP6 variables
While most of the variables from CMIP6 remain unchanged, there are a few which have been edited. We have automatically flagged the variables which might have had one of the following fields edited since CMIP6.
- Table/physical parameter (i.e. Has the variable’s compound name changed)
- Cell methods
- Cell measures
- Dimensions
- Units
- Positive direction
The updates to these fields have mostly been made to fix errors in CMIP6 variables. Variables with changes have been flagged in the ‘Flag – variable change since CMIP6’ field. Where a variable is flagged, we recommend comparing to the CMIP6 CMOR tables to clarify the differences. The Technical Implementation Subgroup is working on some software to facilitate this comparison, but this is not available at the time of the v1.0 release. Please also note that not all changes have been flagged. We are working on an automated check for changes by v1.1 release.
Associating MIPs with Opportunities
During the v1.0beta release, we offered MIPs the chance to tag themselves to Opportunities. The options offered to MIPs were:
- If an Opportunity will produce science which is essential for their MIP. This is indicated in the field ‘MIPs – high priority.
- If the science produced by an Opportunity would be relevant for their MIP, but is not essential for their science goals. This is indicated in the field ‘MIPs – lower priority’.
Please note, we only received responses from a few MIPs so this information is incomplete. We will continue to collect this information to allow modelling centres to inform their Opportunity selection via MIPs.
Making pressure levels more uniform
To make the Data Request easier to implement, the Atmospheric Author Team have proposed to move all daily and monthly data requested on the CMIP6 pressure levels plev8 and plev7h onto 19 pressure levels (plev19 from CMIP6). This has been implemented in v1.0.
Sub-daily data requested from the downscaling and emulator communities are still requested on a smaller number of pressure levels, due to the potential data volume bloat a move to 19 levels could cause. Data on plev3, plev7c, and plev27 remain unchanged.
The thematic author teams will still accept feedback on this change, so please contact the CMIP IPO if you have any feedback on this.
Variable names
In this release of the Data Request, variables are still identified by their compound name, as in CMIP6 (e.g. Amon.ta). This unique identifier is under discussion in the WIP and is could change in the future.
2D and 3D ocean variables
The DR TT and Oceans & Sea Ice thematic team are aware of inconsistency in definition and naming of 2D and 3D variables – this will be resolved in advance of v1.1 release.
Accessing the Data Request
The Online Database
The full Data Request can be explored online at https://bit.ly/CMIP7-DReq-v1_0.
Many users will not have used Airtable, or navigated through the complex CMIP Data Request database before. While it may seem complex at first, Airtable is an extremely powerful tool which makes viewing complex data structures much more simple when you know how to use it. Therefore we encourage users to take some time getting used to the platform in order to make navigation easier for yourself in the future.
We have created some guides to help you navigate and use the CMIP7 Data Request database. Access the Airtable guides at https://bit.ly/CMIP7-DReq-guidance.
The GitHub Software Package
The Data Request Task Team’s Technical Implementation Subgroup (DR-TISG) have started work to create Python code to allow users to interact with the CMIP7 Data Request. It will provide an API and scripts that can produce lists of the variables requested for each CMIP7 experiment, information about the requested variables, and in general will support different ways of querying and utilising the information in the data request.
This software is under active development and will continue to evolve following the v1.0 release. The DR-TISG welcome any feedback and/or contributions to the software via GitHub. Full details are provided in the GitHub README file.
All variable metadata is available in the exported Data Request content; however, at this stage it has not been converted into CMOR format. This will be discussed during the launch events.
Flat list of the variables
The new structure of the Data Request is centred around Opportunities, which allows for important description of, and justification for, inclusion of output variables in the Data Request. Additionally, the database structure of the Data Request allows for improved consistency of technical metadata across the many variables in CMIP. However, we appreciate that many Data Request users find a flat list of the variables useful. This flat list is available in two ways:
- In the Variables tab of the online Airtable database. This can be exported to CSV format by clicking the MASTER button, then selecting ‘Export to CSV’.
- In the GitHub, a JSON export of variable metadata from the Airtable database is available at via the GitHub Software repo.
Providing feedback
The Data Request Task Team will launch a second public consultation on the content of v1.0 soon. This consultation will clarify feedback mechanisms.
MIPs and Modelling Centres can continue to provide feedback using the Excel spreadsheets and/or Variable Comment forms circulated during the v1.0beta release. Content of the Request has been updated slightly since v1.0beta. You are welcome to continue using the v1.0beta spreadsheets shared previously.
v1.0 launch events
The Data Request Task Team are holding a virtual launch event following the Data Request v1.0 release. The event is aimed at MIPs and Modelling Centres, though anyone from the CMIP Community is invited to register.
During the session, the Task Team will present an overview of the request, including descriptions of the changes in structure since CMIP6, an overview of the information and tools available to you, and an introduction to the CMIP7 Data Request software package. There will be opportunities for questions and discussion throughout the session.
The Data Request Task Team is also interested in how MIPs and Modelling Centres would like us to engage with you in the coming months, especially with two future Data Request versions planned for release in January (v1.1) and March (v1.2). Please come ready to participate in this interactive discussion.
Please note, this event is being repeated across two sessions to enable participation from colleagues working in different time zones. You only need to attend one of the two meetings.
Register for Session 1: Tuesday 26 November, 17:00-18:00 UTC
Register for Session 2: Wednesday 27 November, 08:00-09:00 UTC
The new CMIP7 Data Request structure and more background information
The Data Request Task Team have developed an activity that works with community representatives to devise a controlled list of high priority variables that facilitate the majority of user needs. They proposed the following structure of the next Data Request to the CMIP Panel and WGCM Infrastructure Panel (WIP). The Panel and WIP both approved the structure.
The Data Request includes variable definitions and the mapping of variables against the justification for the request expressed in terms of the opportunities that the data will generate. This will take the form of a controlled list of high priority variables that serve both the majority of user needs and create a harmonised set of data requests which balance scientific demand for data against modelling centre and infrastructure capacity.
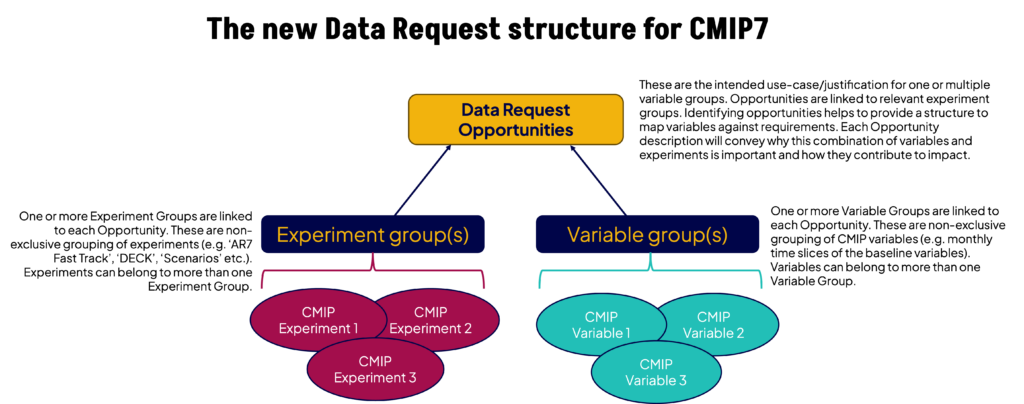
The new CMIP7 Data Request Structure, showing how Experiment Groups and Variable Groups are linked to Opportunities.
The thematic author teams process
Five thematic author teams have been set up to develop the controlled list of high priority variables through through an IPO-supported and Data Request Task Team coordinated paper writing process.
An open call was conducted for authors and reviewers for the thematic papers:
- Impacts & adaptation (call closed on 30 November)
- Ocean & sea-ice (call closed on 01 March 2024)
- Atmosphere (call closed on 08 March 2024)
- Earth system (call closed on 08 March 2024)
- Land & land-ice (call closed on 08 March 2024)
Appointed authors can be viewed here. The Author teams will be running open meetings and other engagement initiatives with modelling centres during this process.
Variable selection
Author teams as well as the wider CMIP community have been asked to define:
- What data is requested, including CF metadata,
- Why it is needed and why it is a priority,
- Who will make use of it
- How it will be used.
Alongside discussing individual variables, the following have been asked to define:
- Experiment groups: non-exclusive grouping of experiments (e.g. ‘AR7 Fast Track’, ‘DECK’, ‘Scenarios’ etc.)
- Variable groups: non-exclusive grouping of variables (e.g. monthly time slices of the baseline variables).
- Opportunities: intended use-case/justification for one or multiple variable groups. Opportunities are also linked to relevant experiment groups.
Creating opportunities
Identifying opportunities helps to provide a structure to map variables against requirements. Each opportunity description conveys why this combination of variables and experiments is important and how variables and experiments contribute to impact.
Each opportunity includes:
- A high-level description of the science and/or societal use and impact
- A time slice to specify a block of years for which data is needed.
- Experiments and variables that link to the opportunity. Some experiments and variables will be linked to more than one opportunity.